Algoritmy a jejich implementace
V letním semestru 2018/2019 přednáším o tom, jak se algoritmy implementují na reálných počítačích. Bude to přednáška na pomezí teorie a praxe. Očekávat můžete rychlokurs pokročilých partií jazyka C, stručný přehled charakteristik hardwaru důležitých pro optimalizaci algoritmů, základy paralelního programování na SMP/NUMA a zajímavou teorii s překvapivými výsledky v praxi – například cache-oblivious algoritmy.
Přednáška se koná v úterý od 10:40 v pracovně S322. Cvičení ve středu od 17:20 v SU1 vede Filip Štědronský.
Co se přednášelo
| datum | téma |
|---|---|
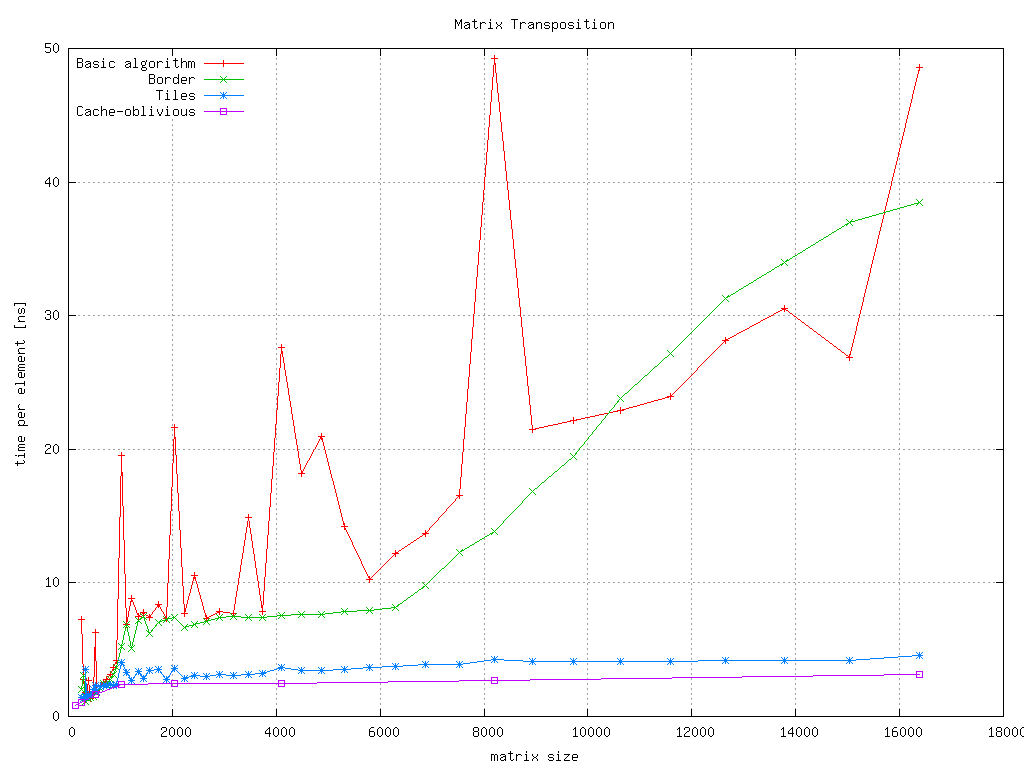
| 27. 2. | Motivace: záhada transponování matice. Úvod do hlubin jazyka C11: Typový systém a reprezentace objektů (na co se lze spolehnout a na co už ne). Viz Medvědův průvodce po Céčku. |
| 28. 2. | Pokračování na cvičení: Výrazy, literály a operátory. Vedlejší efekty a synchronizační body. |
| 5. 3. | Pokračování Céčka: Aritmetika s ukazateli. Jak číst deklarace, kvalifikátory (const, volatile, restrict) a třídy uložení (static a spol.). Funkce, jejich deklarace. Příkazy. |
| 6. 3. | Pokračování na cvičení: Funkce s variabilním počtem parametrů. Fáze překladu. Preprocesor a pravidla nahrazování maker. |
| 12. 3. | Jak číst přeložené programy. Základy assembleru na IA32/AMD64: datové typy, registry, adresní módy, volací konvence. Různé překlady téhož programu. |
| 13. 3. | Pokračování na cvičení: Standardní knihovna, GCCčková rozšíření jazyka. |
| 19. 3. | Cache a jejich hierarchie. Správa paměti, TLB a jejich interakce s cachemi. Paměti SDRAM a jejich rozhraní (aproximace). Co z toho plyne pro programátory? Graf rychlosti přístupů k paměti a věštění z něj. Spusťte si kreslítko grafů (viz repozitář) na svém stroji a zamyslete se nad jeho výstupem. |
| 26. 3. |
Drobnosti: va_arg na AMD64, sdílení TLB mezi procesy pomocí PCID.
Jak procesor zpracovává instrukce. Pipelining, superskalární a out-of-order vykonávání,
spekulativní vyhodnocování a predikce skoků.
Techniky predikce skoků (podmíněných i nepřímých).
Různé implementace architektury x86.
|
| 2. 4. | Počítače s více procesory: SMP, protokoly MESI a MOESI pro koherenci cache. Jak programovat na SMP: Procesy a vlákna. Různé druhy atomických operací, bariéry, thread-local storage. |
| 9. 4. | Programování na SMP: sdílení paměti, zámky, semafory, condition variables. Příklad s frontou. Mnoho způsobů, jak si pořídit race condition, deadlock nebo livelock. Granularita zámků. Implementace zámků a futexy. Transakční paměť softwarová i hardwarová. |
| 16. 4. | Paměťový model C11. Zámky ve sdílené paměti mezi procesy. NUMA. Skutečný SMP hardware: Vícejádrové procesory, HyperThreading a Bulldozer. Různé topologie víceprocesorových strojů, FSB, HyperTransport, QuickPath. Spusťte si na svém počítači machinfo (viz repozitář), co asi vypíše? Zvyšujeme počet procesorů: NumaConnect, AMD Magny-Cours a triky v jeho implementaci L3 cache. Directory-based koherence a HT-Assist. |
| 23. 4. | Další implementace x86: AMD Bulldozer, AMD Zen. Bezpečnostní problémy spekulativního vyhodnocování: různé druhy postranních kanálů, Meltdown, L1TF. |
| 30. 4. | Bezpečnostní problémy: různé varianty Spectre, retpolíny. Vektorové programování: MMX, SSEn, AVX. Další rozšíření instrukční sady: CRC32, AES, … Netemporální přístup k paměti a prefetche. Jak se vektorové jednotky používají z Céčka. |
| 7. 5. | Co přinesl projekt Larrabee: Xeon Phi a AVX-512, kruhové sběrnice ve Skylake Xeonech. Příklad ze života: Jak jsme programovali sorter pro LibUCW. Interní třídící algoritmy a jejich chování. Externí třídění aneb proč disk není páska. |
| 14. 5. | Přednáška se nekoná. |
| 21. 5. | Jarní sklizeň bezpečnostních problémů: MDS (a.k.a. Fallout, RIDL a ZombieLoad). Třídění s keší/diskem: více-cestný Mergesort a odpovídající dolní odhad. |
{kind=link}
Zkoušky
Ke zkoušce je potřeba znalost odpřednesené látky (bez technických detailů hardwaru). Na zkouškové termíny se prosím hlaste v SISu; po domluvě vás rád vyzkouším i jindy. Zápočet můžete složit až po zkoušce.
Odkazy
- Repozitář s materiály k přednášce:
- Videozáznamy z přednášek z roku 2015
- Různé texty k přednášce:
- Céčko a Unix:
- Norma jazyka C11
- Single Unix Specification v4 (nástupce POSIXu)
- System V ABI (pro 32-bitový mód; na Linuxu berte s rezervou)
- AMD64 ABI (64-bitový mód)
- Dokumentace ke GCC
- comp.lang.c FAQ (pozor, mírně zastaralé)
- přednáška Jonase Skeppstedta o paralelním programování, v níž je mimo jiné pěkně převyprávěn paralelní paměťový model C11
- Hardware:
- What Every Programmer Should Know About Memory od Ulricha Dreppera
- Sandpile – prakticky vše o procesorech x86/amd64
- Dokumentace od procesorů AMD a GPU ATI (za přečtení stojí zejména AMD64 Architecture Programmer's Manual a Software Optimization Guide)
- Totéž od Intelu
- Optimalizační triky:
- Bit Hacks – různé triky s čísly a bitovými operacemi
- Software optimization resources Agnera Foga
- Teorie:
- Practical Data Structures – bakalářská práce Michala Pokorného, mimo jiné o cache-oblivious datových strukturách
- Cache-Oblivious Algorithms and Data Structures – úvodní text od Erika Demaine
- The I/O Complexity of Sorting and Related Problems (A. Aggarwal, J. S. Vitter)
- Cache-Oblivious B-Trees (M. A. Bender, E. D. Demaine, M. Farach-Colton)